MVC, MVP, and MVVM are some of the common patterns to guide programmers toward creating decoupled solutions.
The software behaviors that are common to MVC, MVP, and MVVM are:
1)Data Layer / Business Logic (Model): This is the behavior which applies the business logic to the application's data. A Domain Model usually represents the Model where the objects are used to mimic the real world entities.
2) Presentation Layer / UI ( View ): View is responsible for the visual presentation of the application. This behavior displays model information to the user.
3) Application Logic ( Controller, Presentation or ViewModel ): This behavior holds the logic that implements the interaction between the model and the view.
MVC
1)MVC consists of three layers Model, View, and Controller.
2) MVC is a compound pattern
3) It uses a Front Controller pattern that processes Web application requests through a single controller. This enables you to design an application that supports a rich routing infrastructure.
4)It does not use view state or server-based forms. This makes the MVC framework ideal for developers who want full control over the behavior of an application.
5)It provides better support for test-driven development (TDD).
6)It works well for Web applications that are supported by large teams of developers and for Web designers who need a high degree of control over the application behavior.
MVC Steps
Step 1: Incoming request directed to Controller.
Step 2: Controller processes request and forms a data Model.
Step 3: Model is passed to View.
Step 4: View transforms Model into appropriate output format.
Step 5: Response is rendered.
Example:-
Please refer below link
http://www.codeproject.com/Articles/79577/A-Simple-Tutorial-on-Developing-ASP-NET-Applicatio
MVP
1)1)MVP consists of three layers Model, View, and Presenter.
2)In MVP, View and Model are more loosely coupled, providing a clearer separation of concerns.
3)MVP, View is responsible for delegating the user input to the Presenter.
4)MVP, Presenter and View should have a 1-1 relation, with each View having a reference to its Presenter through the interface.
5)MVP, view binds to the Model directly through data binding.
6)In MVP, unit testing is easier, as View knows Presenter through an interface which can easily be mocked.
Example:-
Please refer this link
http://www.c-sharpcorner.com/uploadfile/john_charles/model-view-presenter-mvp-design-pattern-and-data-binding/
MVVM
1)MVVM pattern is a one of the best solutions to handle such problems for WPF and Silverlight application.
2)When you use MVVM pattern for WPF, Silverlight the view wouldn't have the typical event handlers that's so common in UI code.
3)MVVM provides a clear separation between the UI and application logic.
4))The MVVM pattern includes three key parts:
1)Model (Business rule, data access, model classes)
2)View (User interface (XAML))
3)ViewModel (Agent or middle man between view and model)
Example:-
Please refer this link
http://msdn.microsoft.com/en-us/library/gg405484%28v=pandp.40%29.aspx
The software behaviors that are common to MVC, MVP, and MVVM are:
1)Data Layer / Business Logic (Model): This is the behavior which applies the business logic to the application's data. A Domain Model usually represents the Model where the objects are used to mimic the real world entities.
2) Presentation Layer / UI ( View ): View is responsible for the visual presentation of the application. This behavior displays model information to the user.
3) Application Logic ( Controller, Presentation or ViewModel ): This behavior holds the logic that implements the interaction between the model and the view.
MVC
1)MVC consists of three layers Model, View, and Controller.
2) MVC is a compound pattern
3) It uses a Front Controller pattern that processes Web application requests through a single controller. This enables you to design an application that supports a rich routing infrastructure.
4)It does not use view state or server-based forms. This makes the MVC framework ideal for developers who want full control over the behavior of an application.
5)It provides better support for test-driven development (TDD).
6)It works well for Web applications that are supported by large teams of developers and for Web designers who need a high degree of control over the application behavior.
MVC Steps
Step 1: Incoming request directed to Controller.
Step 2: Controller processes request and forms a data Model.
Step 3: Model is passed to View.
Step 4: View transforms Model into appropriate output format.
Step 5: Response is rendered.
Example:-
Please refer below link
http://www.codeproject.com/Articles/79577/A-Simple-Tutorial-on-Developing-ASP-NET-Applicatio
MVP
1)1)MVP consists of three layers Model, View, and Presenter.
2)In MVP, View and Model are more loosely coupled, providing a clearer separation of concerns.
3)MVP, View is responsible for delegating the user input to the Presenter.
4)MVP, Presenter and View should have a 1-1 relation, with each View having a reference to its Presenter through the interface.
5)MVP, view binds to the Model directly through data binding.
6)In MVP, unit testing is easier, as View knows Presenter through an interface which can easily be mocked.
Example:-
Please refer this link
http://www.c-sharpcorner.com/uploadfile/john_charles/model-view-presenter-mvp-design-pattern-and-data-binding/
MVVM
1)MVVM pattern is a one of the best solutions to handle such problems for WPF and Silverlight application.
2)When you use MVVM pattern for WPF, Silverlight the view wouldn't have the typical event handlers that's so common in UI code.
3)MVVM provides a clear separation between the UI and application logic.
4))The MVVM pattern includes three key parts:
1)Model (Business rule, data access, model classes)
2)View (User interface (XAML))
3)ViewModel (Agent or middle man between view and model)
Example:-
Please refer this link
http://msdn.microsoft.com/en-us/library/gg405484%28v=pandp.40%29.aspx
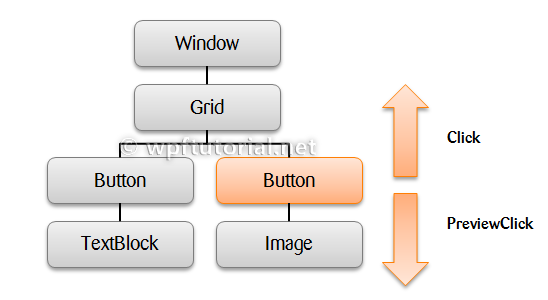 Routed events are events which navigate up or down the visual tree acording to their
Routed events are events which navigate up or down the visual tree acording to their 











Add a comment